
1.环境准备
CentOS7镜像文件、HDFS安装文件、JDK文件、以及一双勤劳的手。
2虚拟机环境搭建
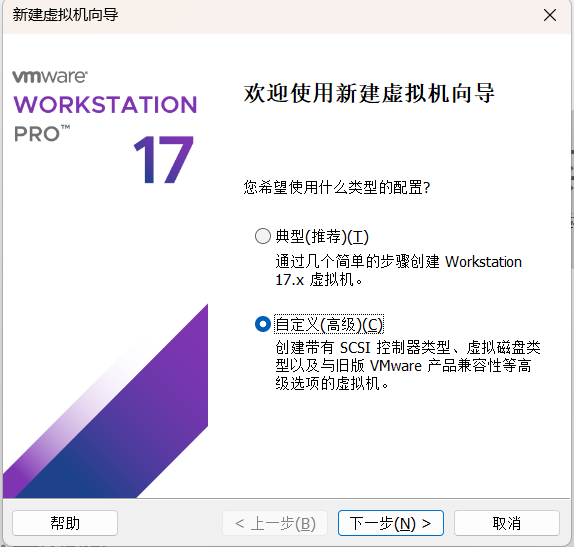
2.1新建虚拟机->选择自定义->下一步
2.2默认选项->下一步
2.3选择稍后安装系统->下一步

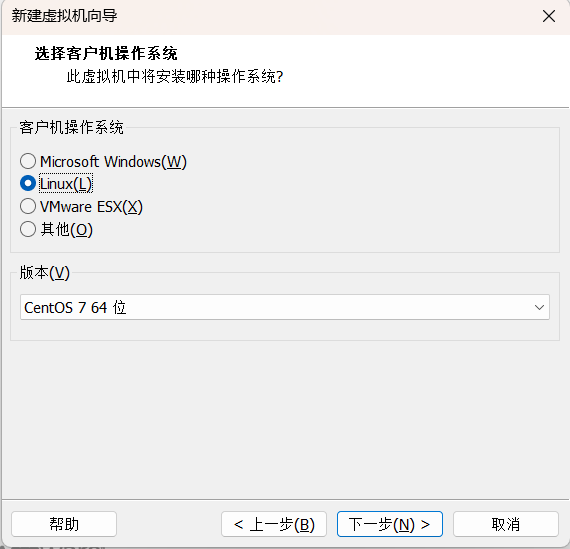
2.4选择Linux CentOS7 64位
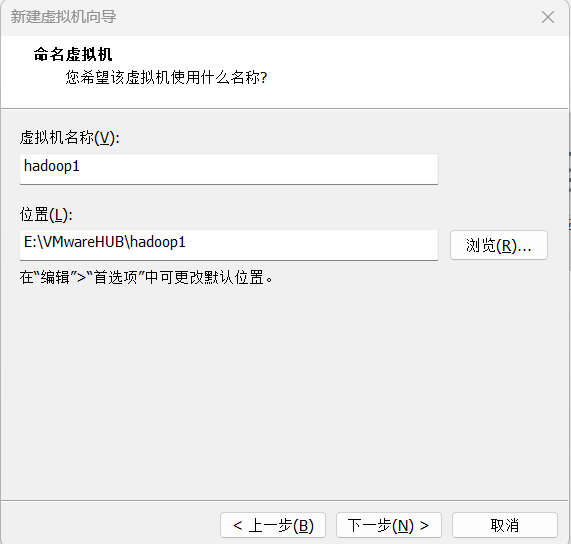
2.5为虚拟机命名,方便区分即可
2.6指定cpu配置,这里仅做示范使用2核
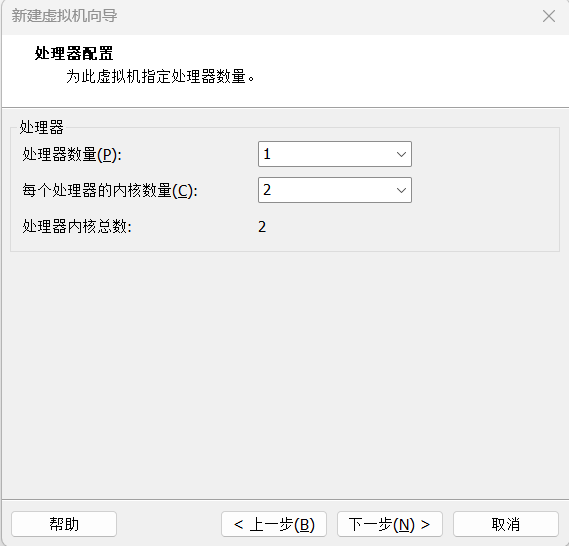
2.7指定内存配置,这里仅做示范使用2GB
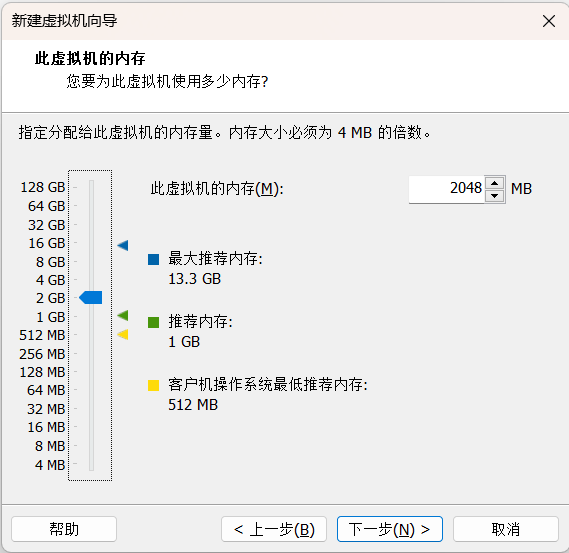
2.8指定虚拟机网络,这里仅做示范,使用桥接网络,需根据实际生产环境配置
2.9剩下的都一路下一步


2.10指定磁盘大小,自定义20GB
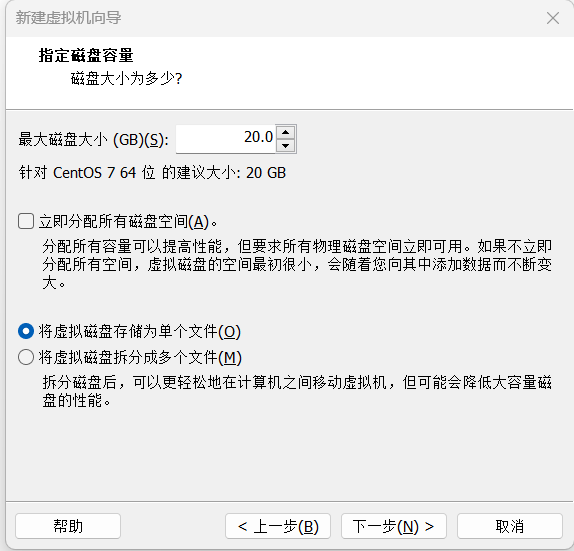

2.11选择自定义硬件

2.12在新CD/DVD(IDE)中选择使用ISO映像文件,选择准备的CentOS7的镜像文件

3.CentOS7环境准备
3.1启动虚拟机
3.2直接回车,安装CentOS7

3.3选择中文->继续
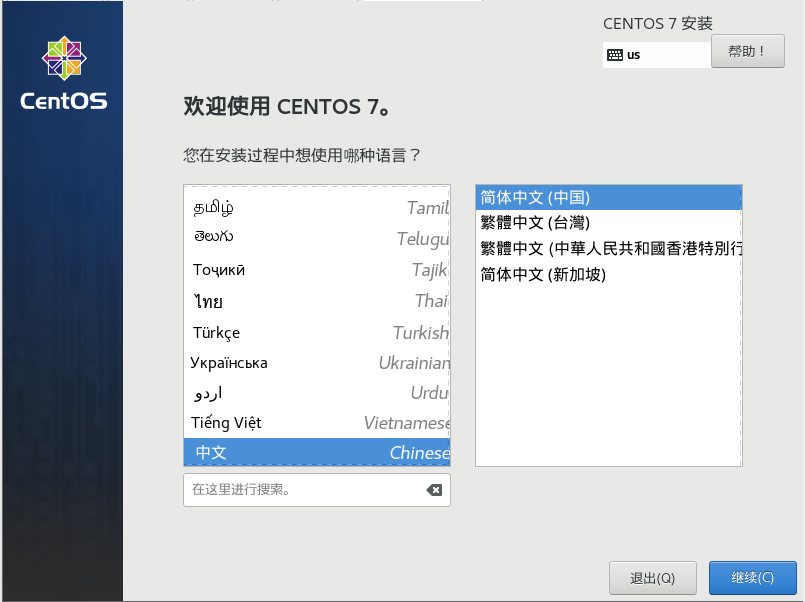
3.4单击安装位置->点击完成->开始安装

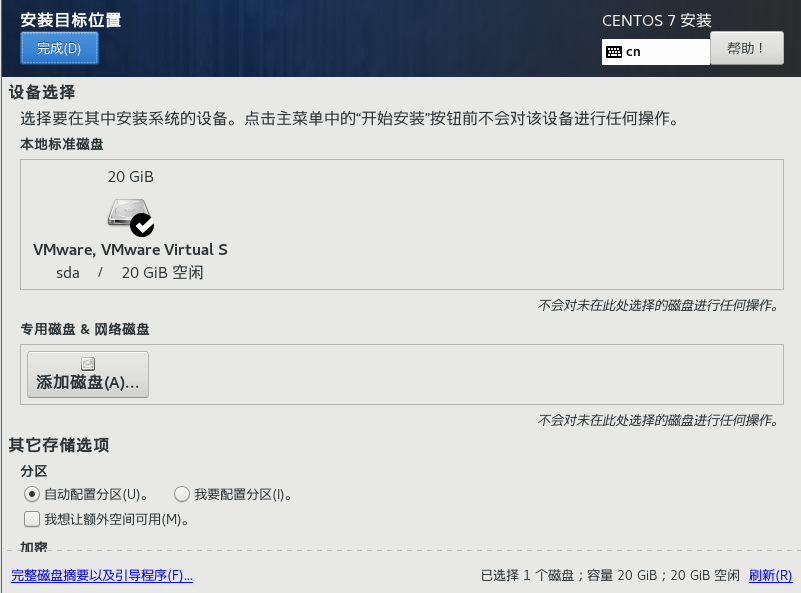
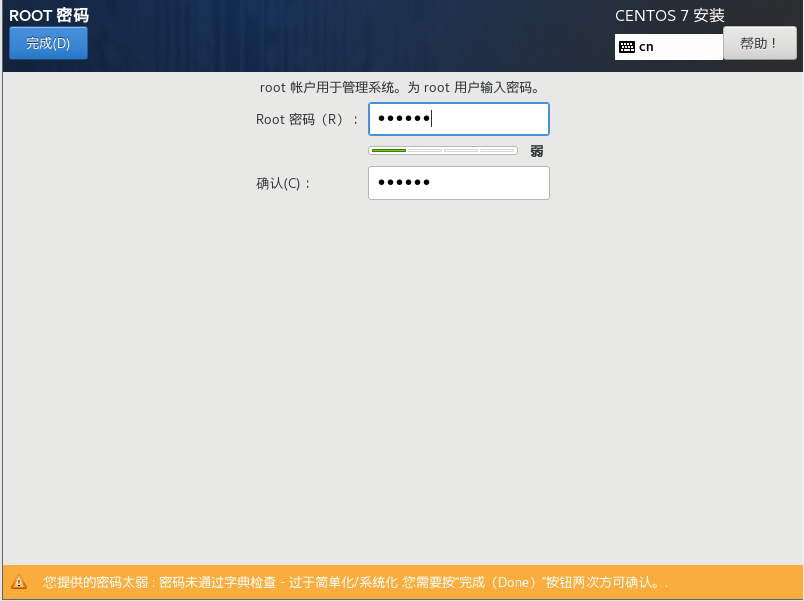
3.5正在安装->单击root密码设置root账号密码(简单密码需要点击两次完成)
3.6重启

4.环境搭建
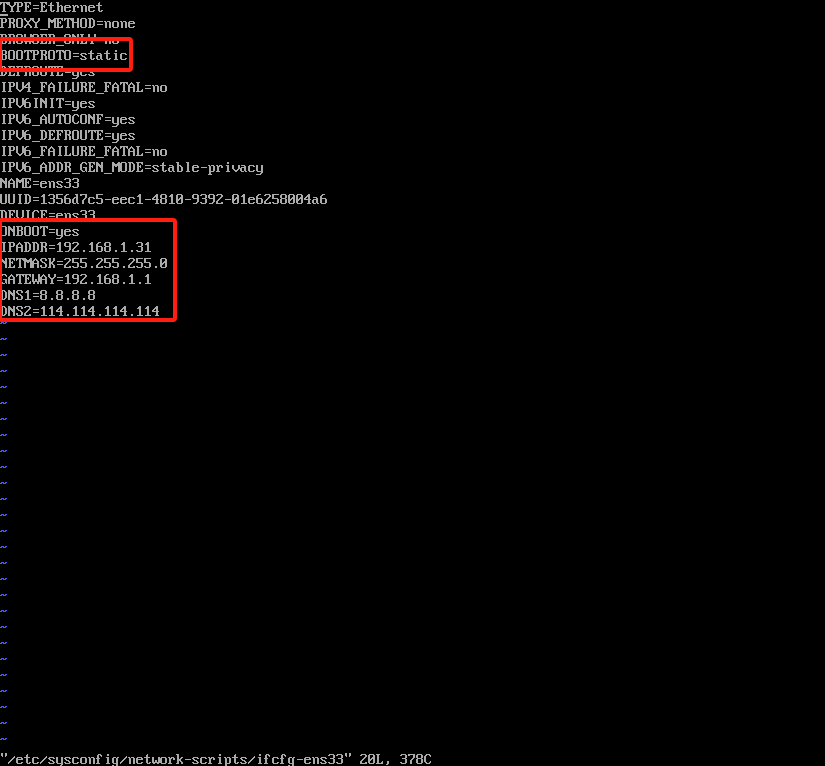
4.1修改网卡配置vi /etc/sysconfig/network-scripts/ifcfg-ens33
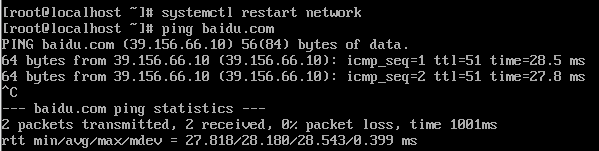
修改完成后重启网卡systemctl restart network,ping通百度,
4.2关闭防火墙和selinux以及防火墙自启(根据实际生产环境而定)
关闭防火墙systemctl stop firewalld
关闭防火墙自启systemctl disable firewalld

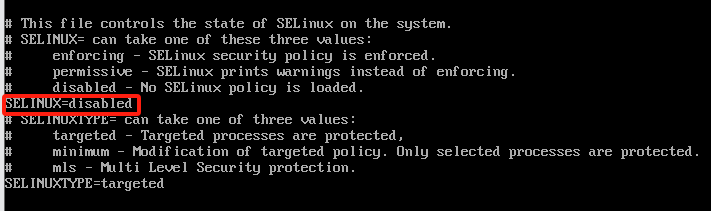
关闭selinux vi /etc/selinux/conf
修改为disabled
4.3修改主机名hostnamectl set-hostname hadoop1

4.4 JDK配置需使用第三方ssh工具上传JDK文件,这里以Xshell为例
上传JDK文件到目录下
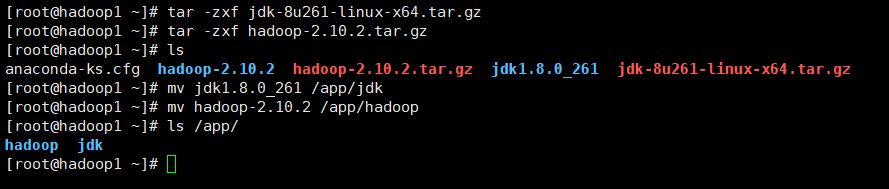
将准备的tar.gz格式的hadoop文件和jdk文件解压,并移动到/app目录下
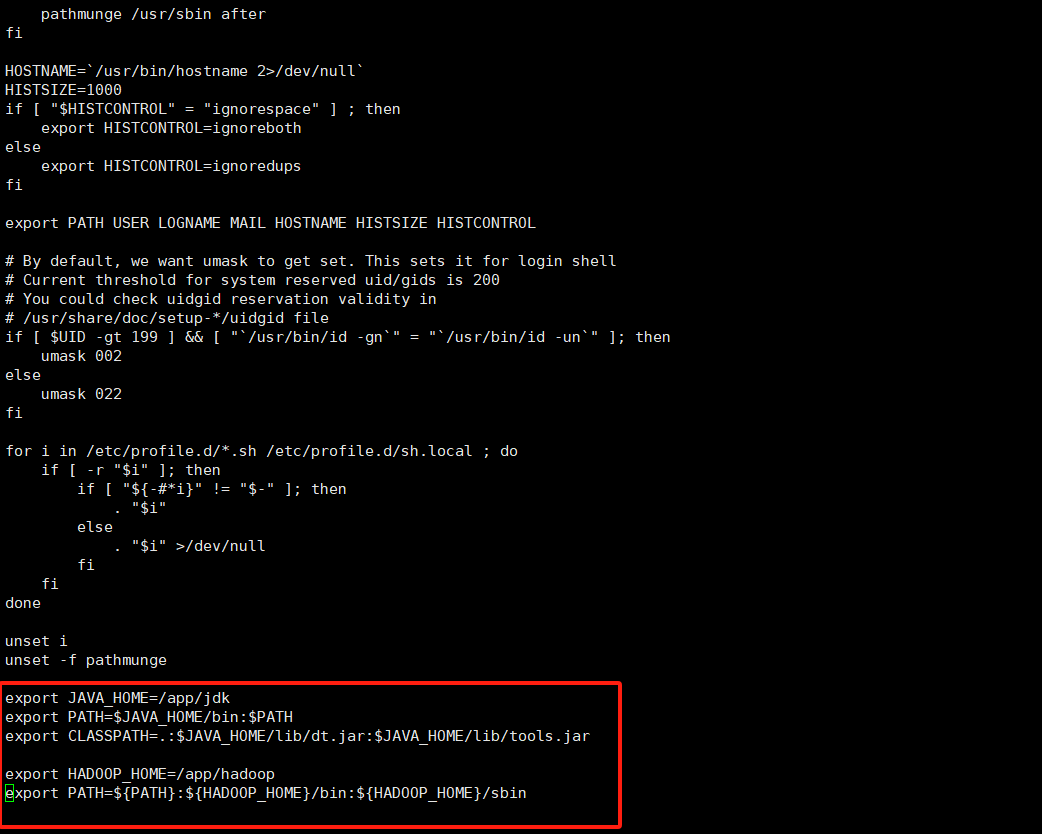
配置环境变量vi /etc/profile在末尾添加export JAVA_HOME=/app/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/app/hadoop
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
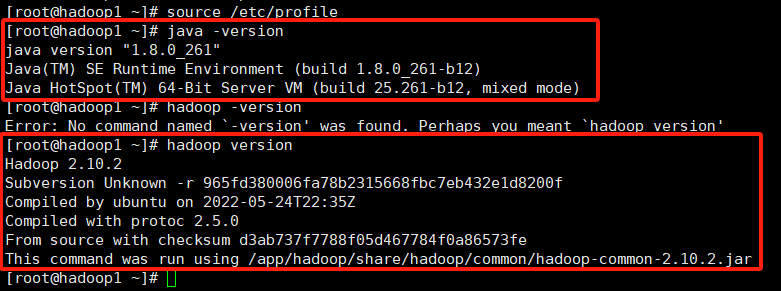
刷新配置文件立即生效source /etc/profile
使用java -version和hadoop version查看是否配置成功
4.5hadoop文件配置cd /app/hadoop/etc/hadoop
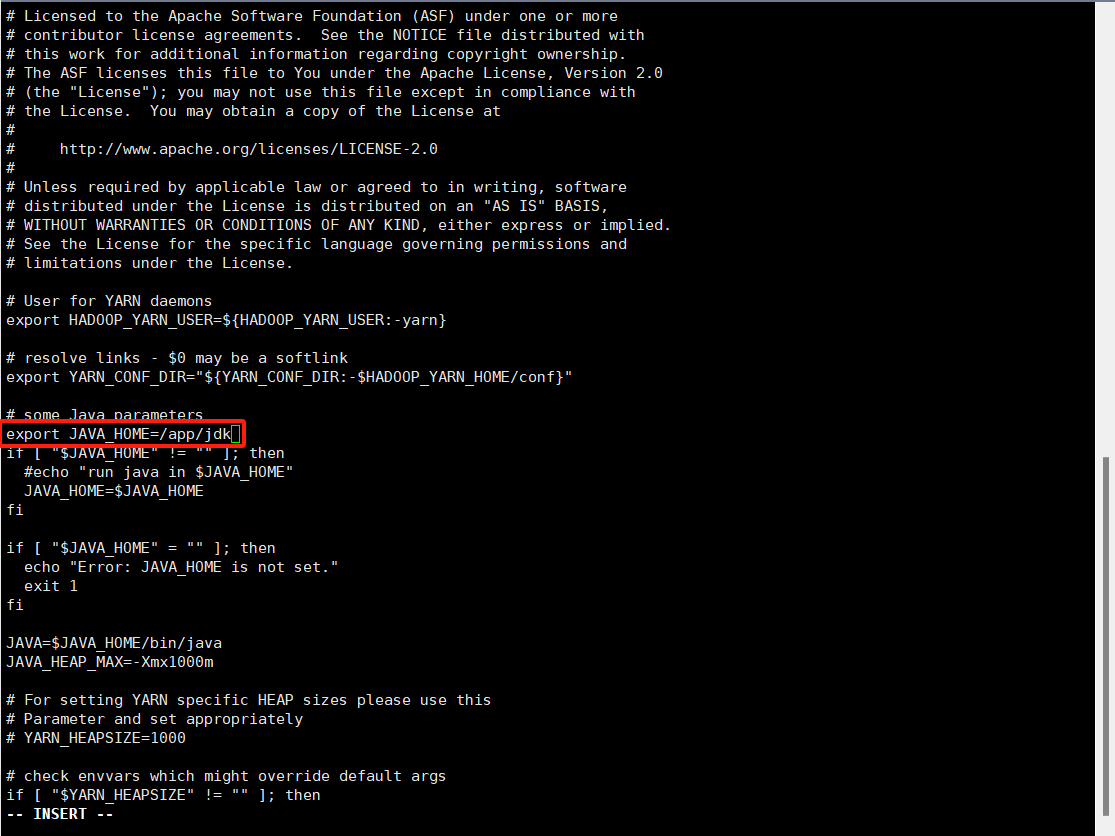
1.hadoop-env.sh文件修改以下配置

2.yarn-env.sh文件修改一下配置
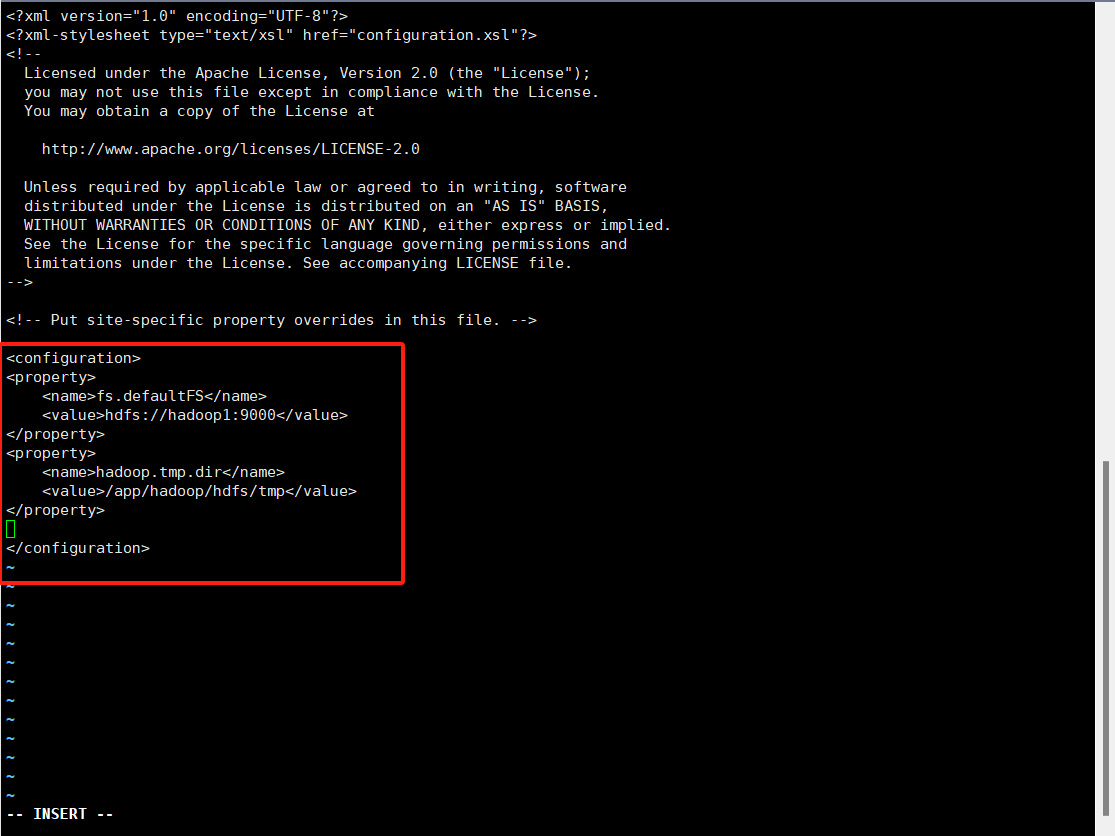
3.core-site.xml修改以下配置
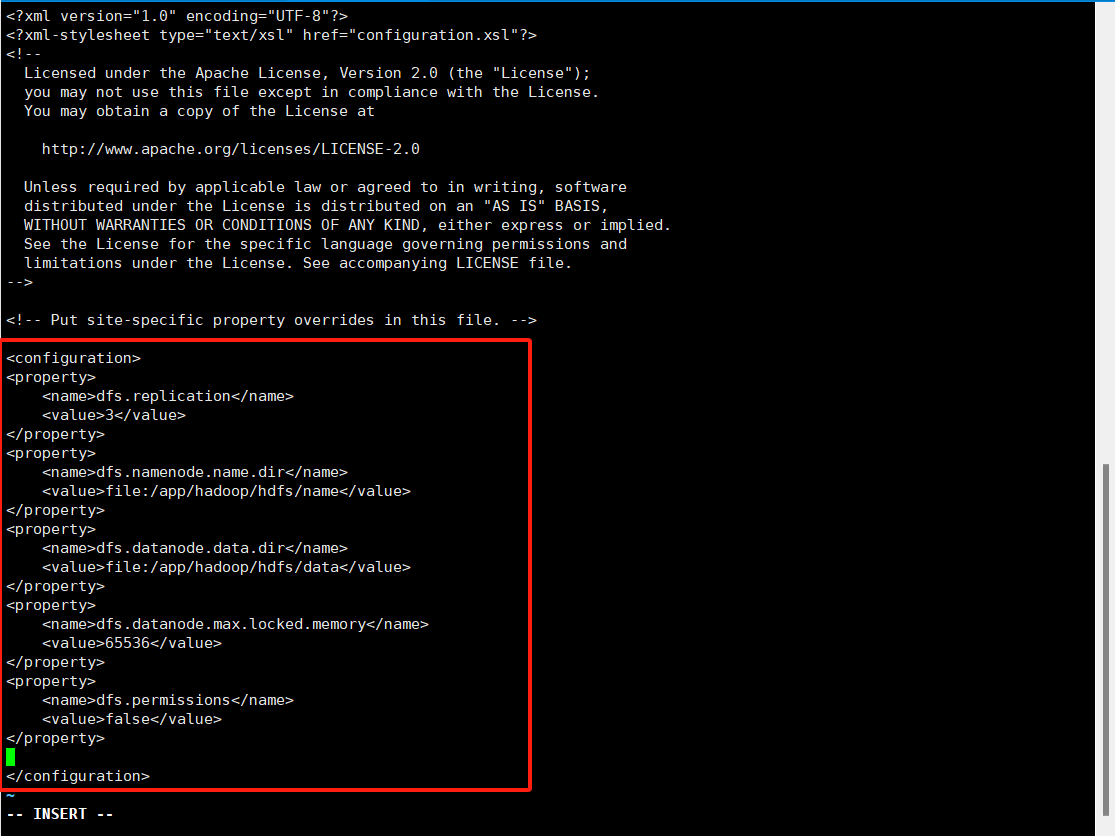
4.hdfs-site.xml修改以下配置
5.mapred-site.xml需要把mapred-site.xml.template拷贝成mapred-site.xml文件进行配置cp mapred-site.xml.template mapred-site.xml

6.yarn-site.xml修改以下配置
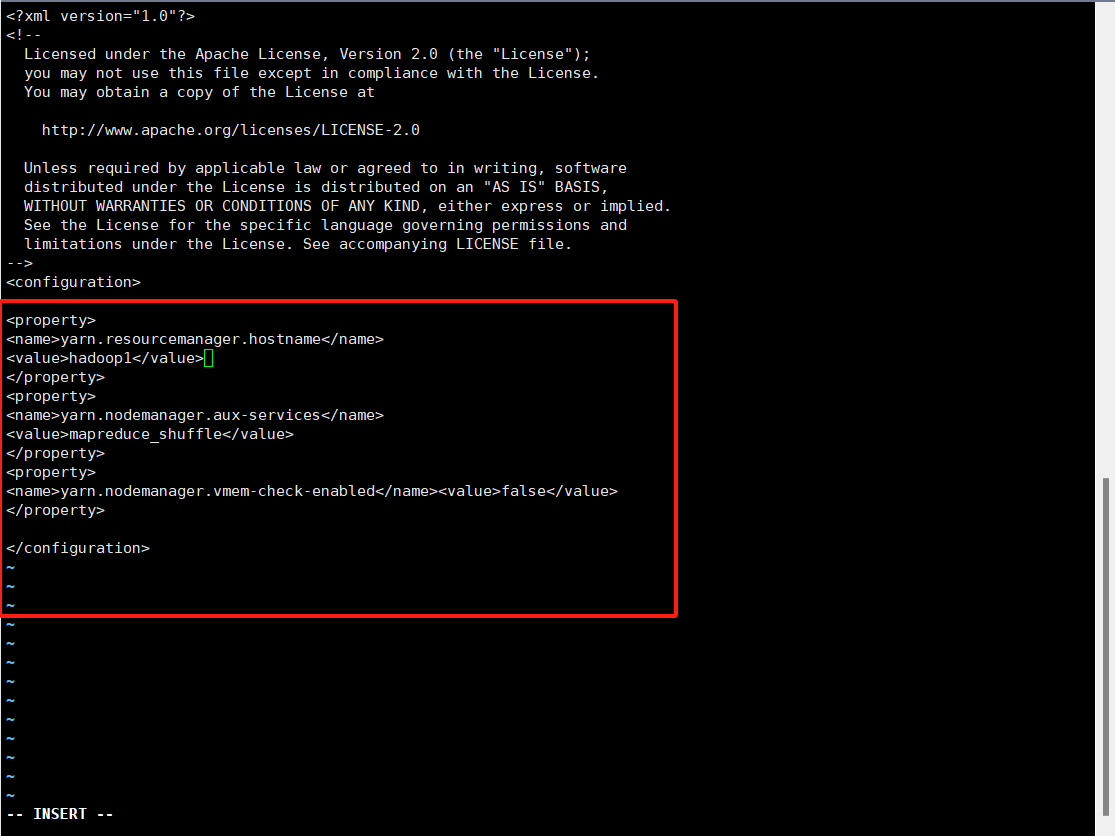
7.slaves文件

8.修改hosts文件
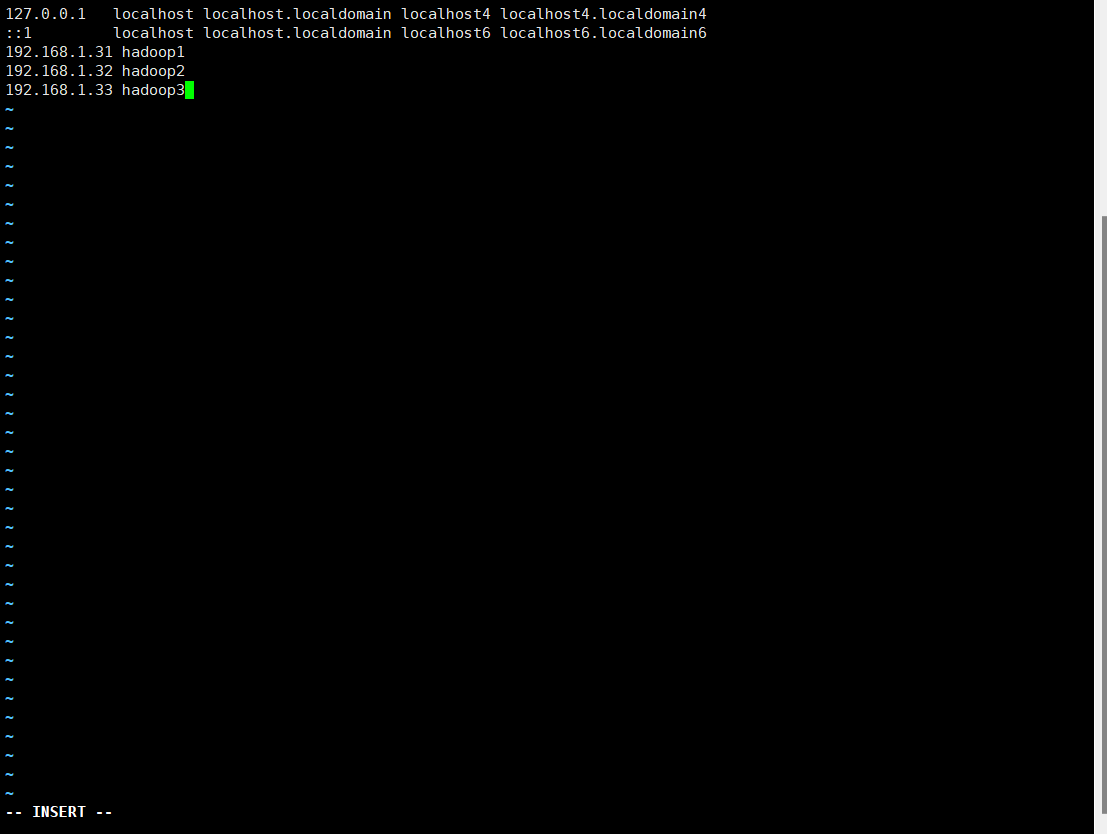
9.将虚拟机关机,复制两份,一共三台
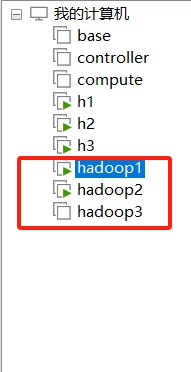
修改复制出的两台虚拟机的配置
一台主机名为hadoop2 192.168.1.32
一台主机名为hadoop3 192.168.1.33
10.设置三台虚拟机之前ssh免密登录
ssh-keygen -t rsa
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
将这四个命令在每一台虚拟机之间都执行一遍
11.在hadoop1机器上执行hdfs namenode -format
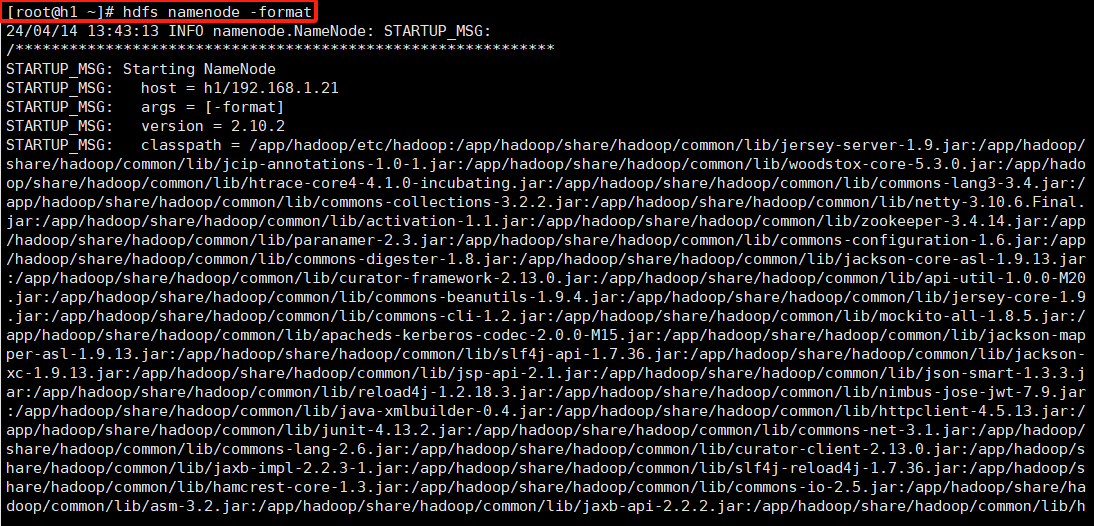
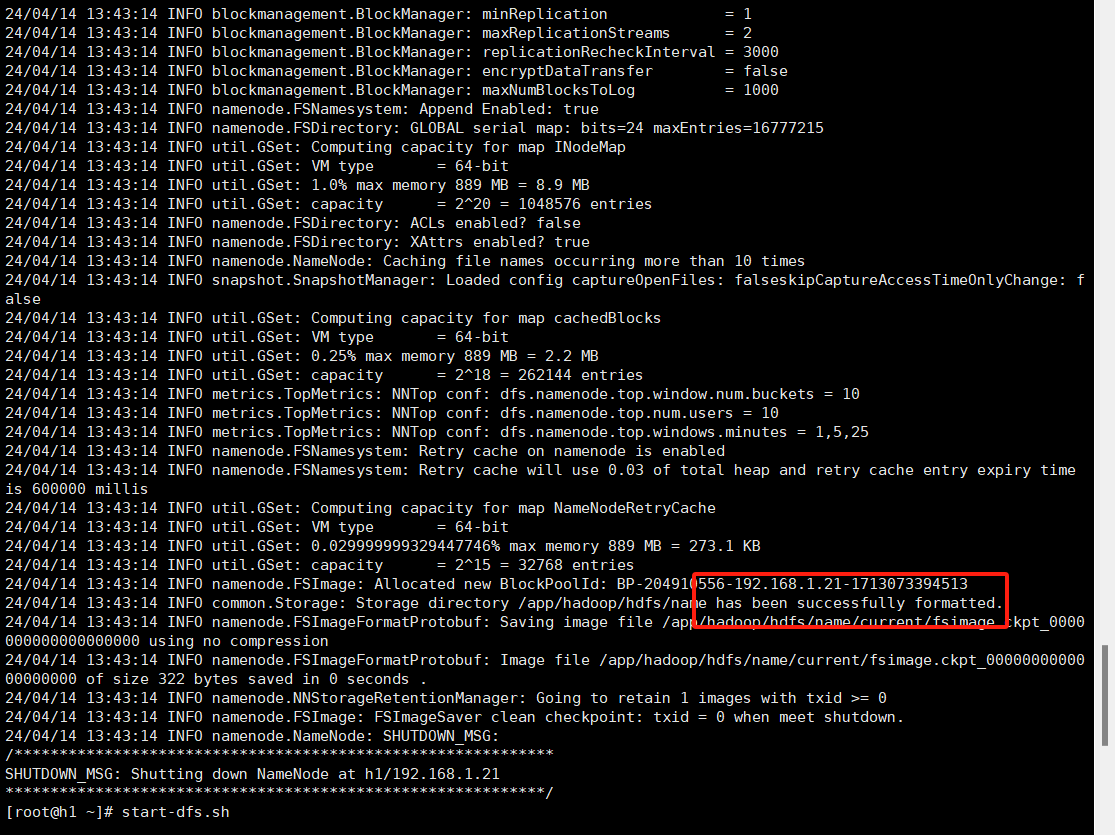
显示successfully则表示成功
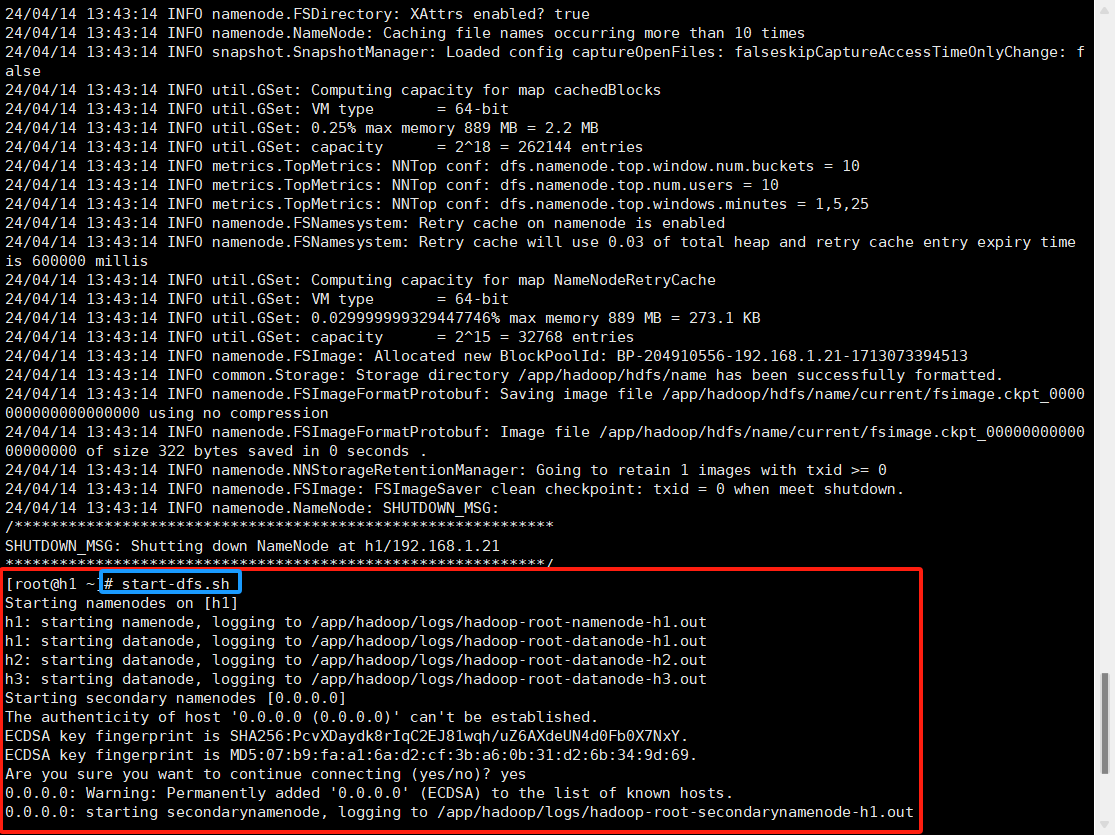
12.执行start-dfs.sh
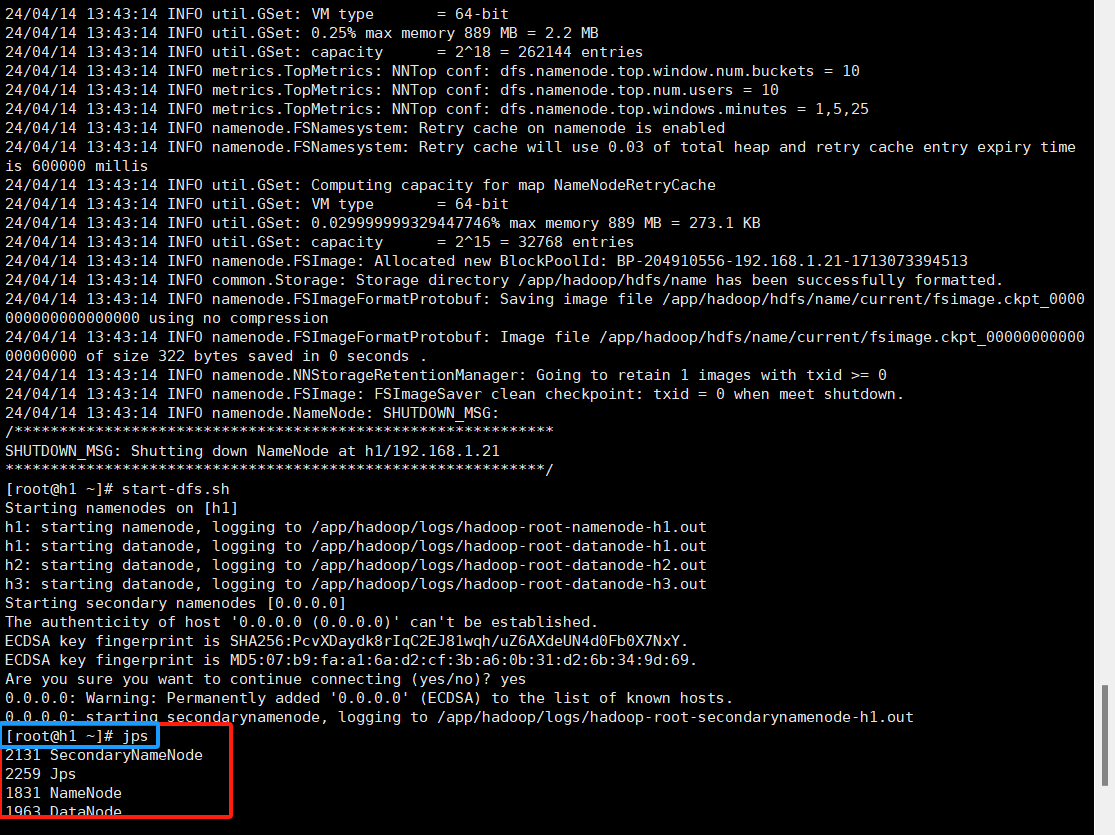
13.使用jps命令查看三个节点信息
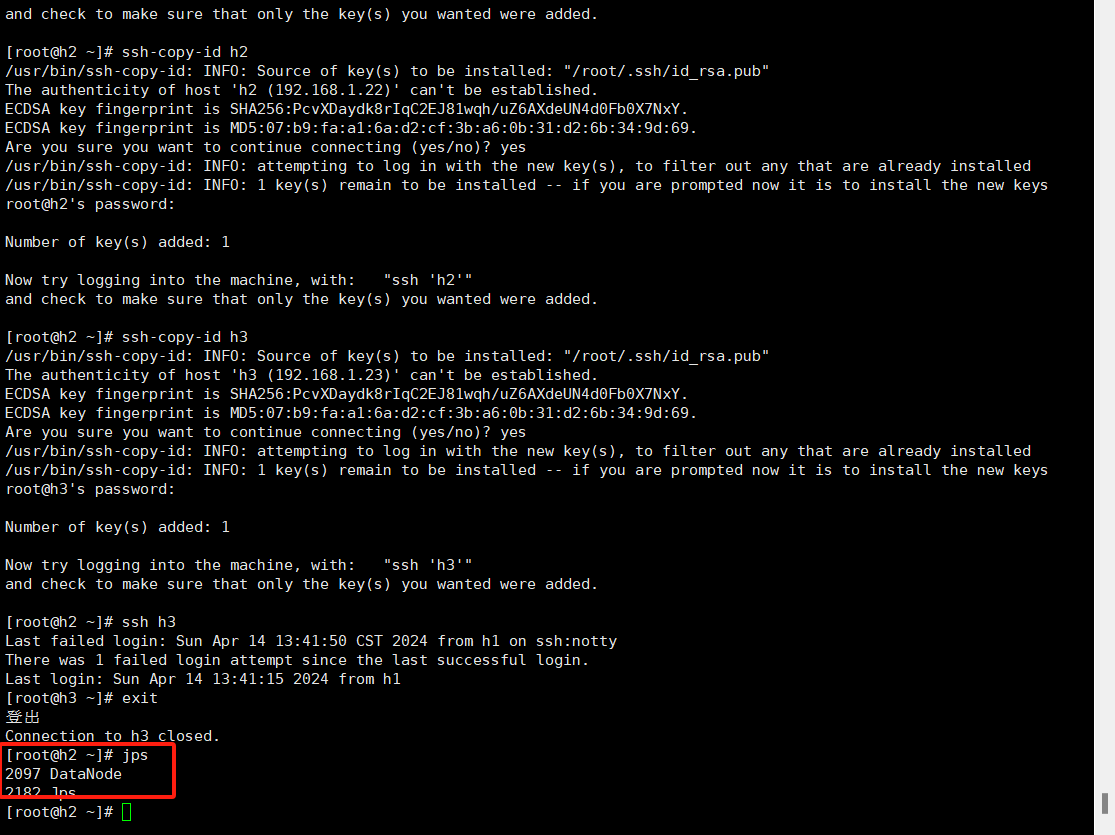
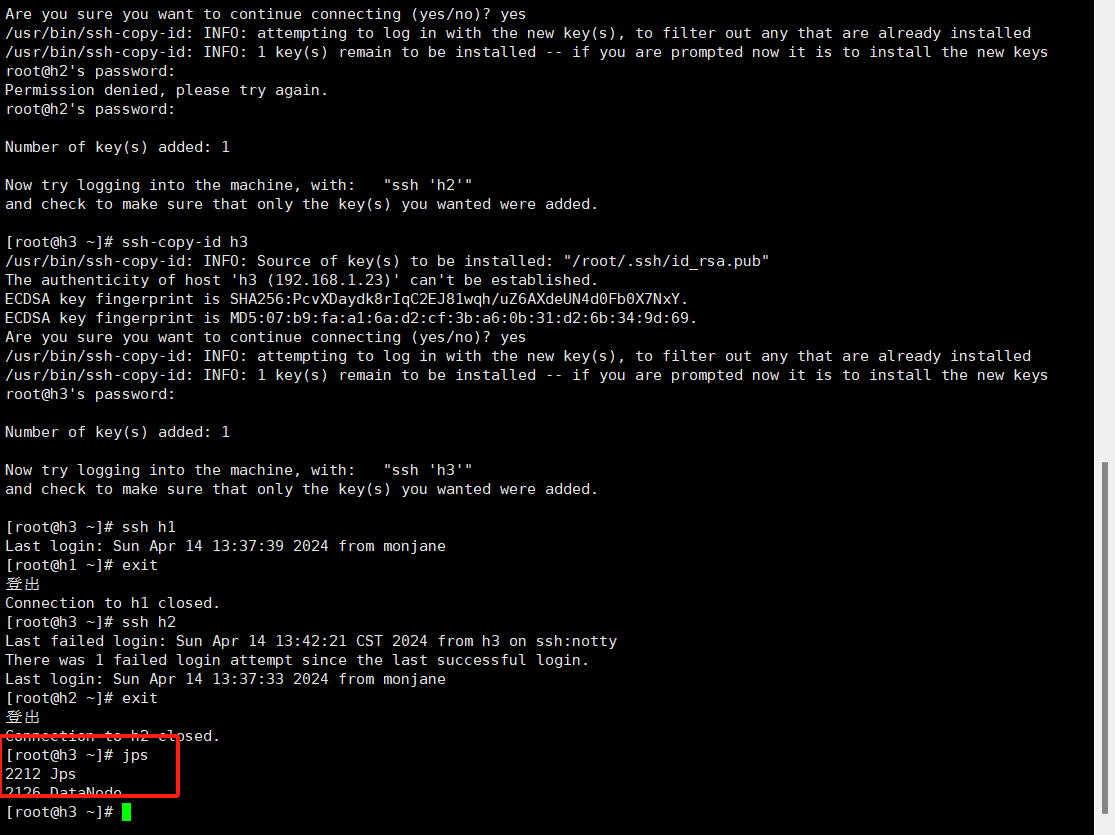
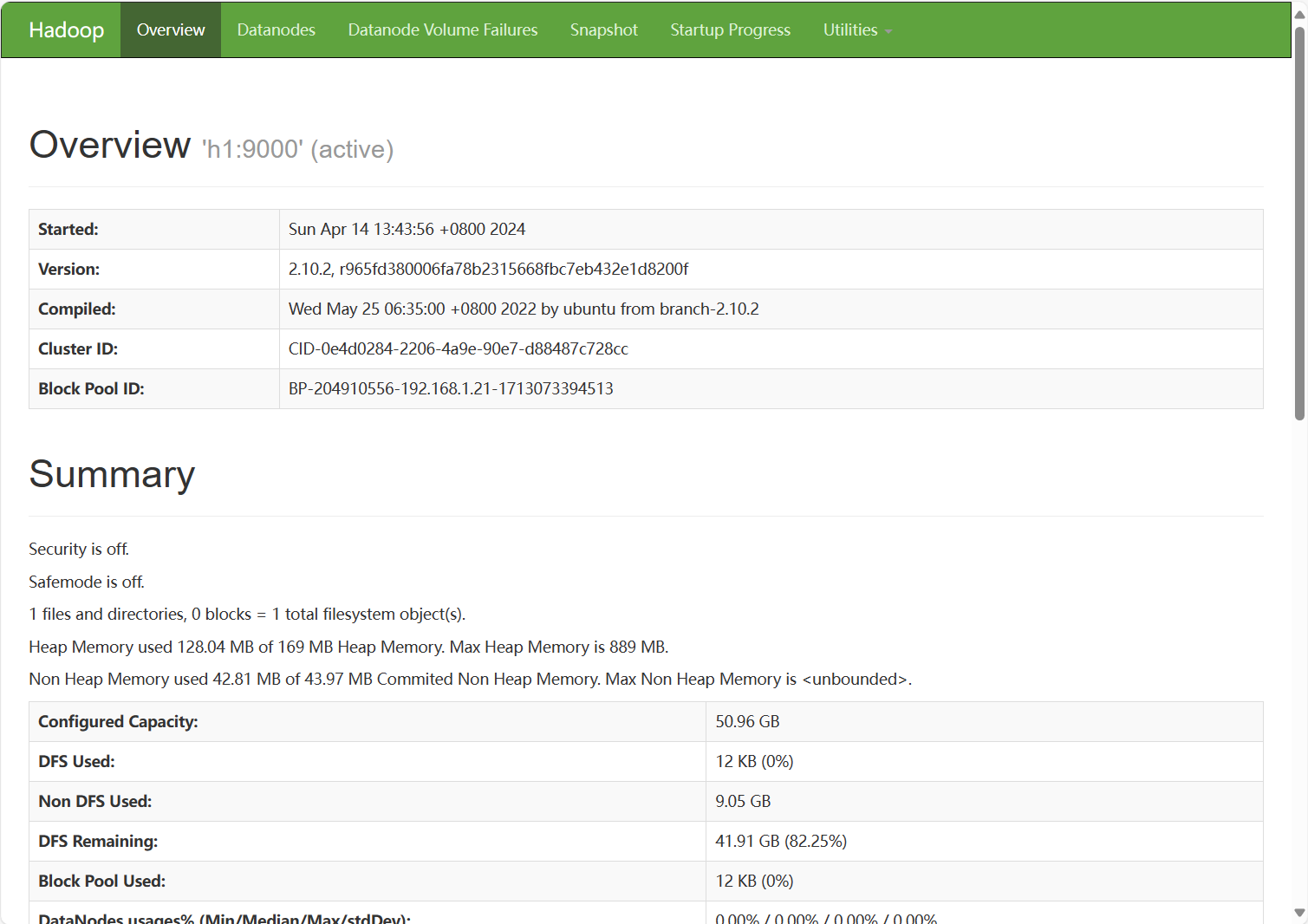
13.浏览器输入http://192.168.1.31:50070/进入面板

Comments | NOTHING